.png)
From this article you will learn:
- why AI appears to “think” while it actually predicts the next word
- what the fundamental differences are between human and artificial reasoning
- what the 7 epistemic fault lines are and how they shape the behavior of language models
- why causality is the biggest limitation of AI
- what the illusion of veracity is and why we so easily trust AI outputs
- which heuristics and biases lead us to overestimate model reliability
- how these limitations translate into real product design decisions
- what epistemic safety is and why it should become a new standard in AI design
- how to design interfaces that support human thinking instead of replacing it
- why in AI design understanding risks and trade offs matters more than inspiration
As creators of digital products, we increasingly integrate large language models (LLMs) into our applications. These tools can write, analyze, and advise with remarkable fluency. From a business and design perspective, however, this fluency can be a trap. Conversational interfaces blur the boundary between reliable knowledge and skillful imitation.
To build safe, useful, and trustworthy products, we must understand that LLMs are not cognitive agents but stochastic pattern completion systems. Generating text with AI is not a process of seeking truth, but a mathematical navigation through a multidimensional graph of linguistic probabilities.
7 Fault Lines (Epistemic Fault Lines)
Despite the surface similarity between human and machine responses, their “reasoning” processes differ radically. Researchers identify 7 fundamental “fault lines” between human and artificial cognition:
- Grounding: We derive knowledge from the physical and social world through multiple senses. AI begins and ends with text, inferring meaning from symbols without access to reality or nonverbal signals.
- Parsing: Humans actively interpret situations and intentions. LLMs perform only mechanical segmentation (tokenization) of input data, which is computationally efficient but lacks semantic depth.
- Experience: Humans rely on episodic memory and intuitive understanding of physics and psychology. AI relies exclusively on statistical correlations in so called embeddings.
- Motivation: Human thinking is driven by emotions, goals, and the need for survival. AI processes are entirely devoid of internal goals, preferences, or empathy. It is pure mechanical optimization.
- Causality: We build mental models of the world by seeking cause and effect relationships. AI connects context based on surface level textual patterns and does not form causal hypotheses.
- Metacognition: We have the ability to monitor our own lack of knowledge and refrain from answering. LLMs do not have such mechanisms. Their architecture forces them to generate responses, which structurally leads to hallucinations.
- Value: Our decisions are shaped by moral values and real consequences, for example the risk of losing reputation. AI responses are only probabilistic predictions with zero personal risk for the machine.
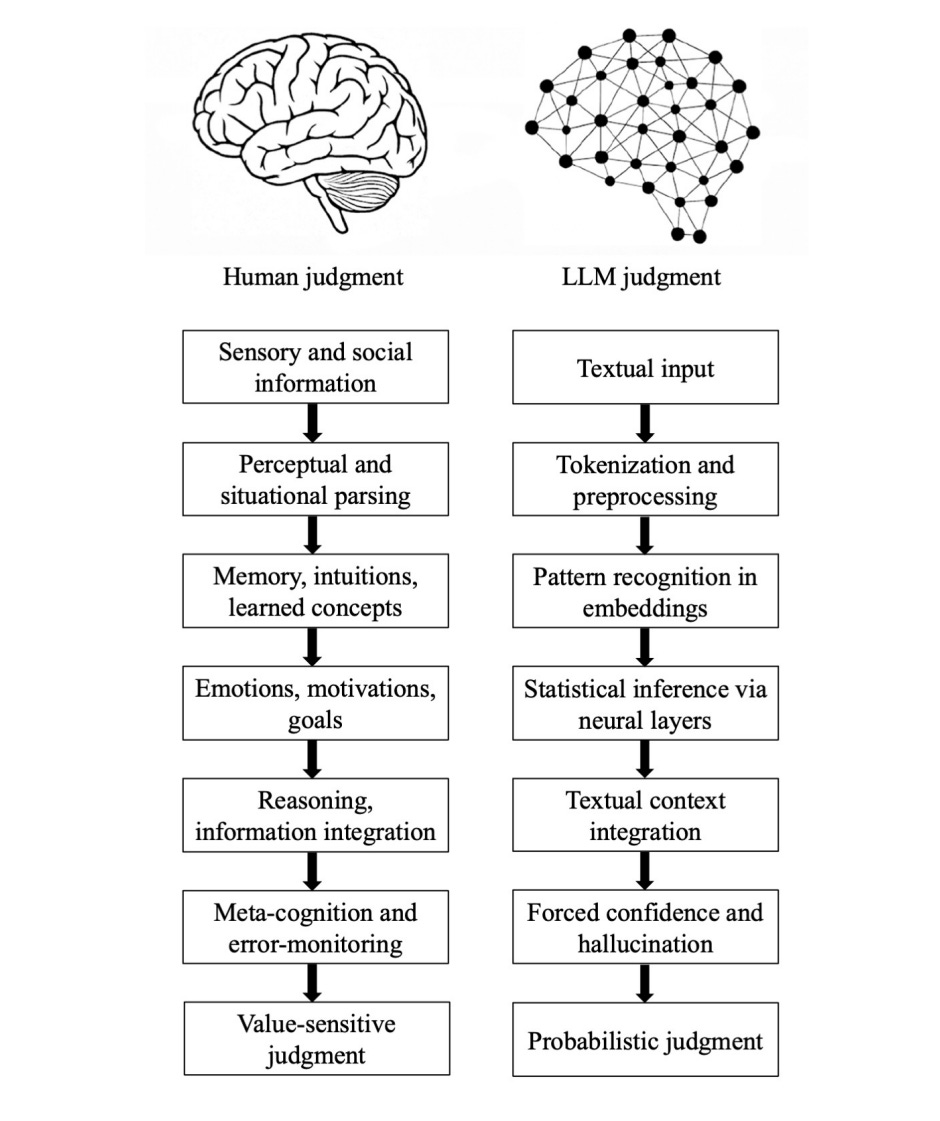
The human and LLM epistemic pipelines, each organized into seven corresponding stages.
AI’s blind spot: causality
Why do models so often fail when a task requires logic? The main difference in reasoning between humans and LLMs is the aforementioned causality.
Humans naturally construct cause and effect models of reality. We can test hypotheses, combine evidence, and imagine counterfactual scenarios such as “what would happen if…”. In language models, what we interpret as “reasoning” is merely the process of integrating words based on massive training datasets. Because LLMs do not track truth relationships but only word correlations, they are highly susceptible to spurious associations and drastically lose performance when faced with causal relationships they have not previously “seen” in the data.
The illusion of veracity and heuristic traps
The greatest threat to users of our products is the so called illusion of veracity. It is a systematic gap between how accurate a model’s response actually is and how accurate it appears to a human.
This phenomenon is driven by psychological shortcuts, heuristics, and cognitive biases that we fall into when interacting with machines:
- Confidence heuristic: In human contexts, confidence strongly correlates with knowledge and expertise. Since LLMs lack metacognition and cannot feel uncertainty, their default operational state is generating text with absolute, authoritative confidence, even when they are completely fabricating information. Users are misled by rhetorical form, equating style with verification.
- Fluency heuristic: As with confidence, in everyday communication we routinely assess credibility based on how easily and fluently someone speaks. Fluency naturally correlates with honesty and subject knowledge. The highly fluent and grammatically correct text generated by LLMs makes us intuitively trust its truthfulness.
- Automation bias and authority attribution: Users tend to overtrust recommendations generated by automated systems. This often leads to mistakenly assigning interfaces, such as chatbots, the role of an expert, which suppresses our critical thinking.
- Political and gender biases: Designers often attempt to correct models through training based on human feedback, for example RLHF, to align them with our values. However, the model does not gain morality through this, it only adjusts its statistics. As a result, these mechanisms can produce the opposite effect, embedding deep political biases into models. This also creates surprising and illogical gaps in reasoning related to gender, as observed in a case where a model strongly refused to verbally insult a woman to prevent a nuclear apocalypse, but accepted torturing her in the same scenario.
These cognitive shortcuts put the user into a state of Epistemia, a situation in which the syntactic and grammatical correctness of AI becomes a substitute for truth. The user “gets an answer”, bypassing the cognitively demanding process of evaluating evidence.
How does this affect product design?
As product creators, we must move beyond evaluating systems solely through the lens of human likeness, surface alignment, and start designing for epistemic safety. Understanding the differences between humans and AI influences key design decisions:
- The end of designing thoughtless interfaces: The mere use of models such as RAG or adding external memory does not solve the problem. It is still mitigating symptoms, not changing the cognitive architecture of AI. You must design processes, workflows, where AI is an assistant, not the final authority.
- Designing epistemic transparency: Instead of a simple label “Generated by AI”, the interface should communicate what the system did not do. It should require labels showing levels of confidence based on evidence, as well as the model’s limitations. When the system “does not know”, the UI must clearly indicate it.
- Managing epistemic friction: In high risk applications, such as law or medicine, it is necessary to intentionally design friction, forcing users to confirm and review key evidence before proceeding, human in the loop. Automating everything is the fastest path to Epistemia.
How to design transparency in AI interfaces in practice?
Designing for transparency in the age of AI requires a shift in mindset. We need to stop adding generic, low value labels like “Generated by AI” to our products. Instead, the interface should honestly and openly communicate which human cognitive processes the system did not perform.
Here is how to translate this into concrete product decisions:
Be explicit about what AI did not verify:
Instead of guessing, users should immediately see in the interface whether the system actually checked sources, tracked its own uncertainty, or even had a “stop mechanism” that would allow it to refrain from answering when data is missing.
Separate facts from guesses:
Design UX in a way that visually distinguishes information supported by hard evidence from content that is merely the model’s statistical guess. Wherever possible, the interface should expose uncertainty, and for critical claims, it should require clear source attribution.
Expose false confidence:
Since we know AI can sound like an expert even when it is fabricating, we need to make that visible. Users should understand that this apparent confidence is often just a writing style, not the result of verified knowledge.
Design “handbrakes” (human in the loop):
When decisions carry real consequences, the system cannot simply output answers. It must require human verification. The interface and workflows should make it clear who pressed “accept” and who takes responsibility for the generated output.
With this approach, our applications will stop encouraging users to switch off their thinking and will instead support them in consciously controlling machines.
How do we develop epistemic competencies in users?
Our role as designers is to support epistemic literacy within our products. Traditional critical thinking is no longer enough. We must implement:
- Pipeline awareness: Interfaces that educate the user. We must show the difference between systems that retrieve hard data and those that merely “synthesize text” by predicting the next words. The user must understand that fluent output does not guarantee a connection to facts.
- Procedural safeguards: UX that builds habits. We should enforce cross checking of information proportional to the importance of the decision. Add references and remind users to seek expert verification.
- Institutional competencies: At the B2B level, design environments that clearly indicate who is responsible for generated content and prevent delegating decision making entirely to generative tools.
Creating products based on LLMs today is not about hiding the limitations of AI behind great copywriting. Truly innovative design is about making the structure of these systems visible in order to protect the most important element of any system: human agency and responsible judgment.
Instead of blindly copying solutions that are still being discovered and tested, it is worth paying attention to the risks they may carry. Because AI design is no longer just about how something looks, but whether it works in difficult scenarios, where it can fail, and what consequences it has for the user. Designers no longer need another gallery of inspiration. They need tools that help evaluate solutions, understand trade offs, and make better decisions.
That is why BehaviorAI was created, a responsible AI design library that combines real world patterns with expert analysis to support design based not only on inspiration but on informed choice. If you work with AI, you are invited to join the testing starting on 21th of April - behaviorai.eu

Quattrociocchi, W., Capraro, V., & Perc, M. (2025). Epistemological Fault Lines Between Human and Artificial Intelligence. arXiv:2512.19466.
